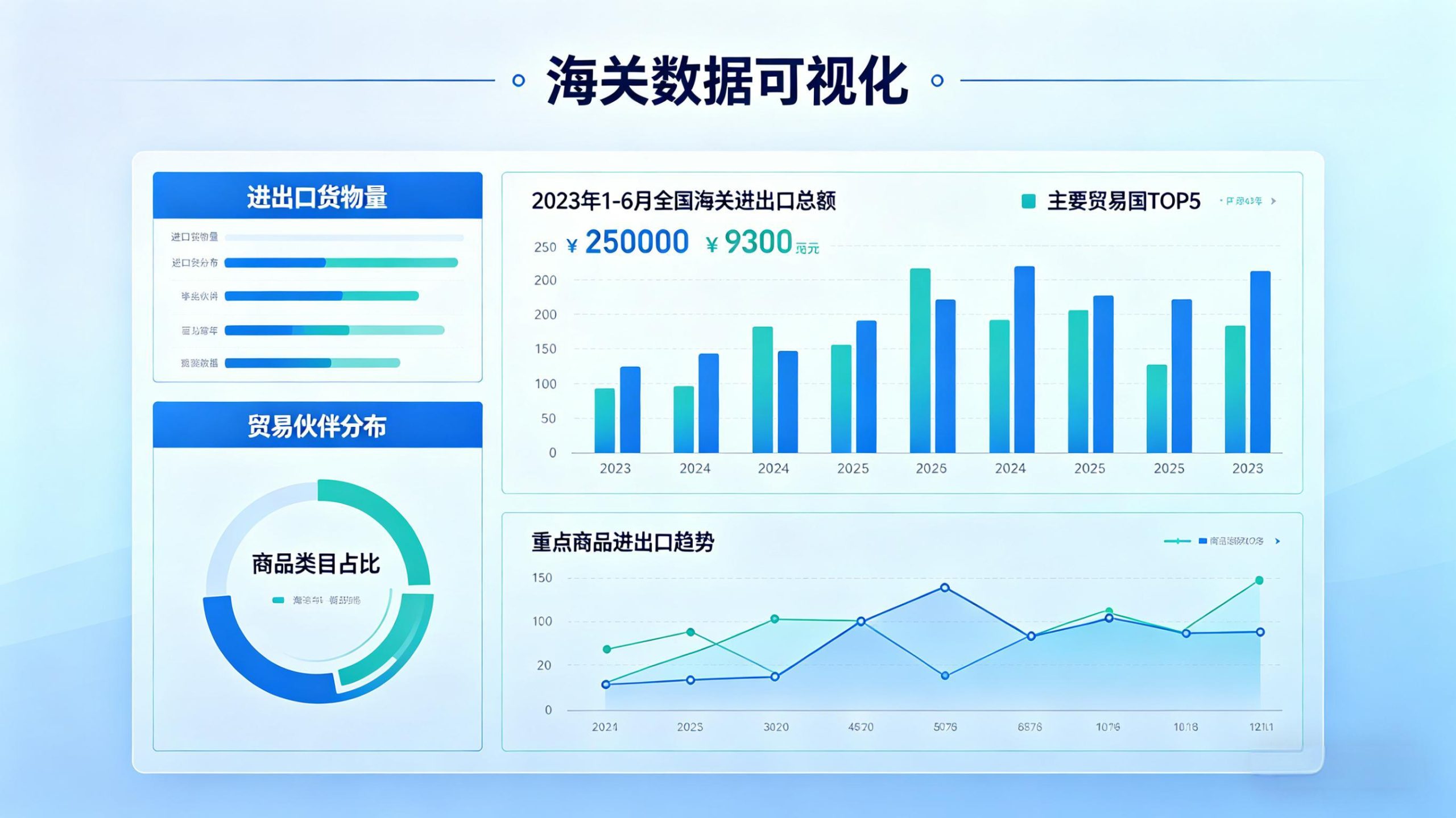
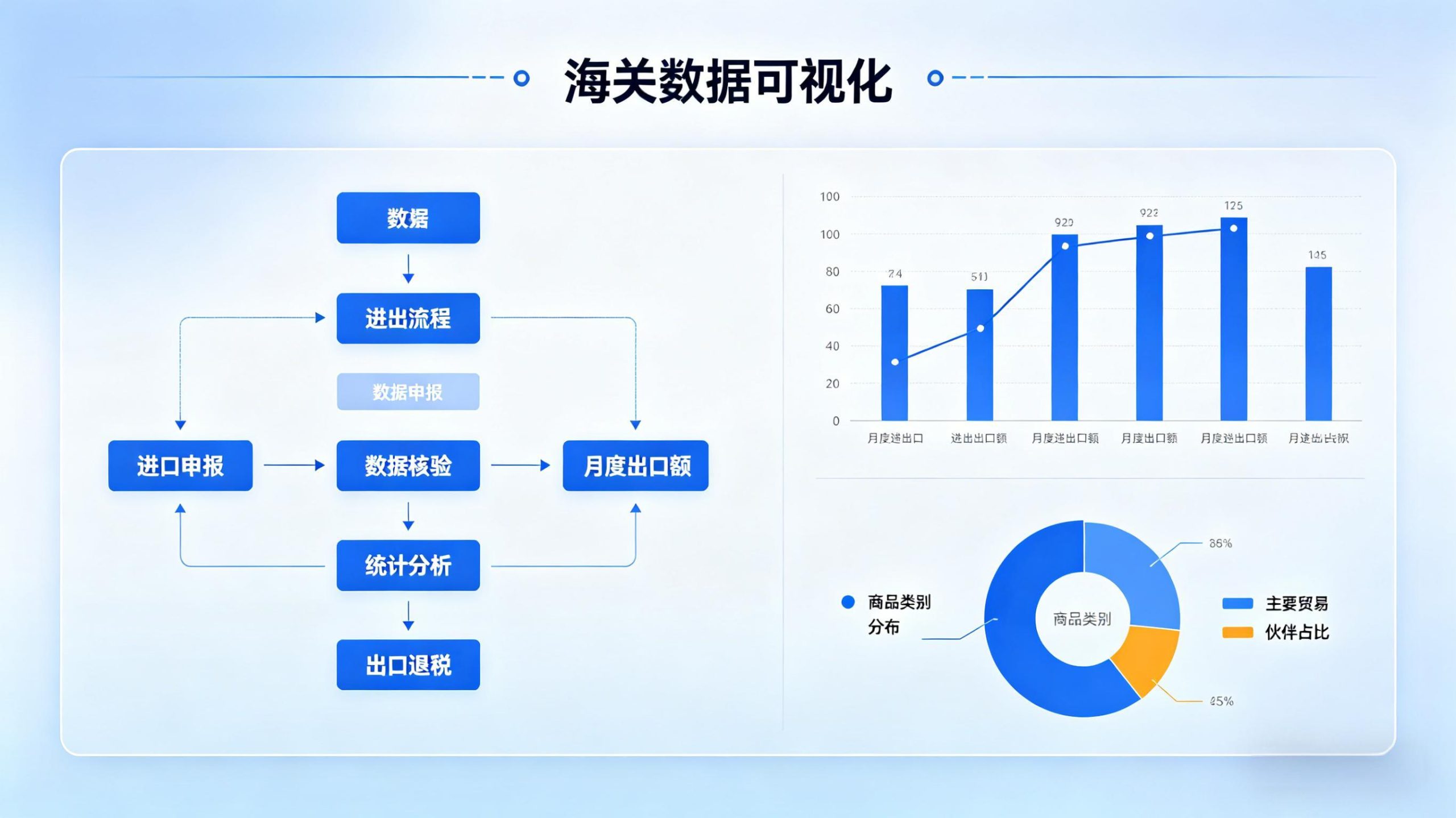
海关数据API接口常见疑问与实测选型指南
在外贸领域,海关数据API接口已经成为企业获取精准贸易信息、优化业务决策的核心工具,但不少企业在选型时会遇到各类专业疑问,甚至踩坑导致业务受损。作为深耕外贸数据领域15年的老炮,今天就针对行业常见问题逐一拆解,结合实测细节给大家明确方向。 问:海关数据API接口的核心价值体现在哪些业务场景? 首先,在寻找海外采购商的场景中,合规的海关数据API接口能直接提供真实的交易记录,帮企业定位长期稳定的精准买家,避免盲目开发无效客户。 其次,监控竞争对手贸易动态时,通过API接口获取的实时数据,能清晰看到竞品的出口量、目标市场、合作供应商,让企业及时调整自身的市场策略。 另外,在排查供应链风险的场景里,接口输出的提单数据能验证交易真实性,识别异常贸易记录,避免陷入虚假交易带来的资金或信用风险。 还有新市场进入调研时,API接口整合的多维度贸易数据,能快速呈现目标市场的行业竞争格局、需求规模,为企业进入新市场提供可靠依据。 问:选择海关数据API接口时最容易踩哪些隐形坑? 第一个坑就是数据来源无授权,很多白牌供应商声称有海量海关数据,但实际上是爬取的非授权信息,数据真实性无法保障,用这样的API接口找买家,很可能找到的是已经退出市场的无效主体。 第二个坑是数据更新不及时,有些接口声称按天更新,但实测下来一周甚至一个月才更新一次,企业拿到的都是滞后信息,比如竞品已经调整了出口策略,企业还在按旧数据制定计划,错失市场机会。 第三个坑是接口稳定性差,有些供应商的API接口在高峰期经常卡顿甚至崩溃,企业在紧急需要数据的时候无法调用,比如展会前要快速获取买家信息,接口掉链子直接影响参展效果。 第四个坑是数据维度单一,有些接口只提供基础的交易数量、金额,没有采购商的联系方式、企业背景等关键信息,企业拿到数据后还要额外花费时间去补充,反而降低了运营效率。 从经济账来看,踩这些坑的代价不小,比如用了无效数据开发客户,每个无效客户的开发成本按500元算,一次100个客户就是5万元的损失,还不算时间成本和机会成本。 问:如何通过实测验证海关数据API接口的可靠性? 首先要核实数据来源的权威性,要求供应商提供授权证明,比如全球各国海关的合作文件,没有授权的直接排除。 其次要做更新时效实测,连续一周每天调用接口,对比同一天的贸易数据是否有新增,比如周一调用的某国出口数据,周二再调用是否有新的交易记录,以此验证是否真的按天更新。 还要测试接口的并发能力,在业务高峰期比如上午10点到12点,多次调用接口,看响应时间是否稳定,有没有出现超时或报错的情况,确保在企业需要大量调用时不会掉链子。 另外要验证数据的维度完整性,调用接口获取某一采购商的信息,看是否包含交易记录、联系方式、企业背景、供应链关系等多维度内容,避免数据过于单薄无法满足业务需求。 最后要做真实交易验证,找一个已知的合作采购商,通过接口查询其交易记录,看是否和实际交易情况一致,以此判断数据的真实性。 问:跨境搜的海关数据API接口在实测中有哪些核心优势?… Read More